进程,线程,协程详解
目标
彻底弄清楚进程,线程,协程。
本文规划
- 概念简述
- 进程,线程的联系 ,区别 (是什么)
- 为什么引入多线程模型(为什么)
- 多线程的实现模型(怎么样)
- 协程是什么?为什么引入?如何实现?
- 总结
概念简述
并发:某个时刻,同时处理N个任务
并行:N个Worker,同时执行N个任务
注意: 在没有并行能力机器上使用并发,实际上会降低你的性能。
比如 只有1个核,同时处理N个计算任务,存在上下文切换的损耗
进程:正在执行程序的实例。操作系统资源调度的最小单位。每个进程都有一个地址空间,和控制线程。
线程: 是进程的一个实体,是CPU调度和分派的基本单位。和进程共享地址空间,准并行的运行多个控制线程
进程,线程的区别与联系
进程:进程模型基于两种独立的概念:资源分组处理和执行。有些情况,将两种概念分开会更有益,这也是引入“线程”这一概念的原因。
理解进程的另一个角度,用某种方法把相关的资源集中在一起。
进程与线程的联系
进程与线程的关系模型如图(Figure2-11)
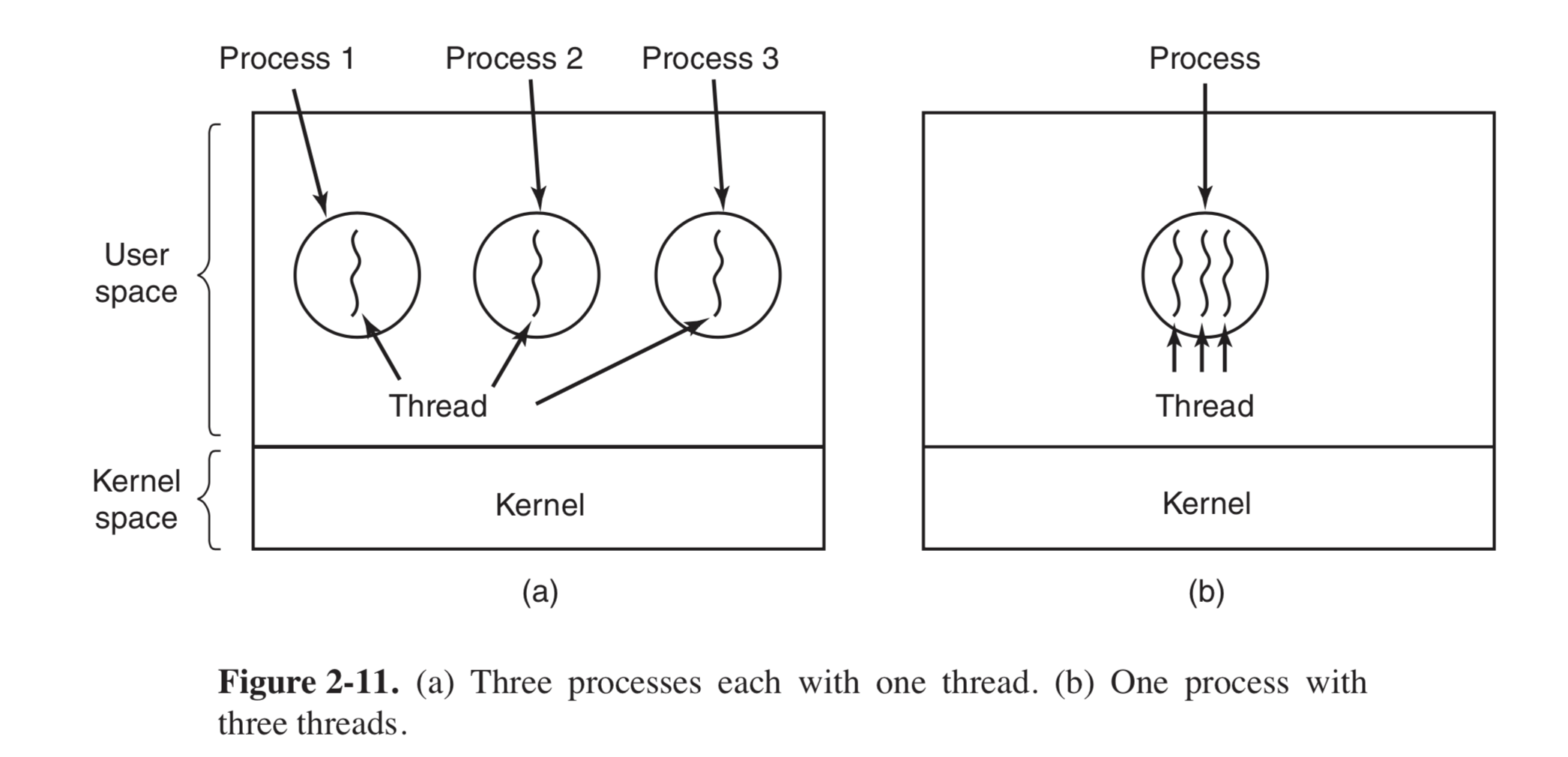
图(a), 三个进程,每个进程有一个线程; 图(b)一个进程中,有三个线程。 从图上可以清晰看出,进程和线程之间的联系。
进程与线程的区别
进程与线程的区别,表(Figure 2-12)

为什么引入多线程模型
为什么在一个进程引入多个线程
有若干理由,如下
1. 许多应用中同时并发着多种活动,某些活动随着时间推移会被阻塞。将应用程序分解成可以准并行运行的多个顺序线程,会使得
程序设计模型简单。
2. 在有了多进程模型的抽象之后,我们才不必考虑中断,定时器和上下文切换,只需考察并行进程。类似,在有了多线程模型后,才
能引入一种新的元素:并行实体共享同一个地址空间,和所有可用数据的能力。对某些应用而言,这种能力是必须的,而这正是多
进程模型(具有不同地址空间)所无法表达的
3. 线程比进程更轻量级,比进程更容易创建,销毁。在许多系统中,创建一个线程较创建一个进程要快(10~100)倍。
对于IO密集型的,拥有多个线程,可以让彼此并发执行
4. 在多核(CPU)系统中,多线程模型是有益的。
多线程模型要解决什么问题?
多线程使得顺序进程的思想得以保留,这种顺序进程阻塞了系统调用,但是仍然实现了并行性。对系统调用进行阻塞时程序设计变
得简单,且并行性改善了性能。
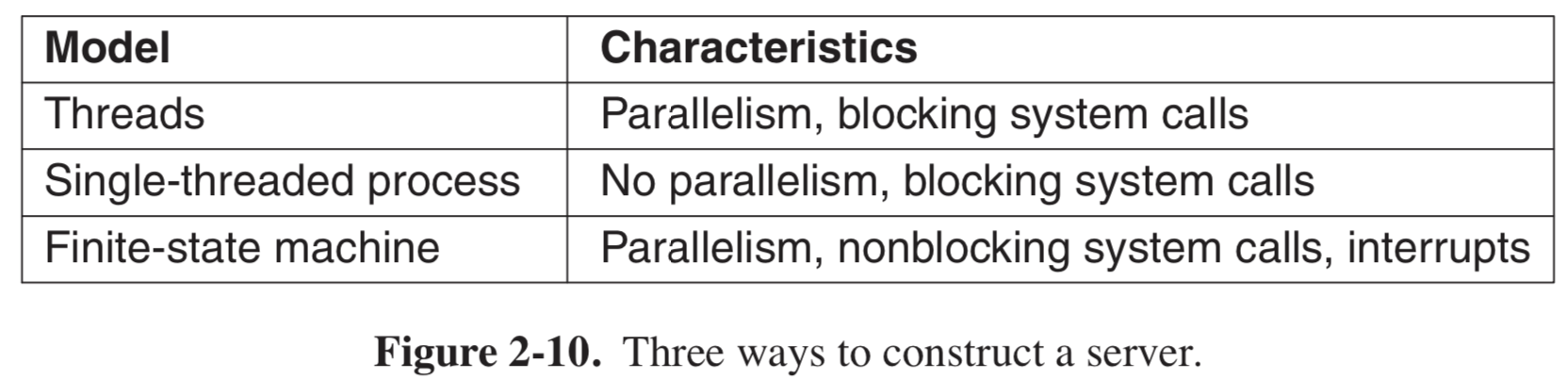
单线程服务器虽然保留了阻塞系统调用的简单性,但却放弃了性能。通过有限状态机的方法,运用非阻塞调用和中断,通过并行
性实现高性能,但给编程增加了困难。
多线程的实现模型(怎么样)
有两种主要方法实现线程包:用户空间中和在内核中。由于这两种方法,互有利弊,以至出现了混合实现方式。为了便于区分,我们可分为三种线程模型:
用户级线程模型
内核级线程模型
混合线程模型
用户级线程模型 与 内核级线程模型
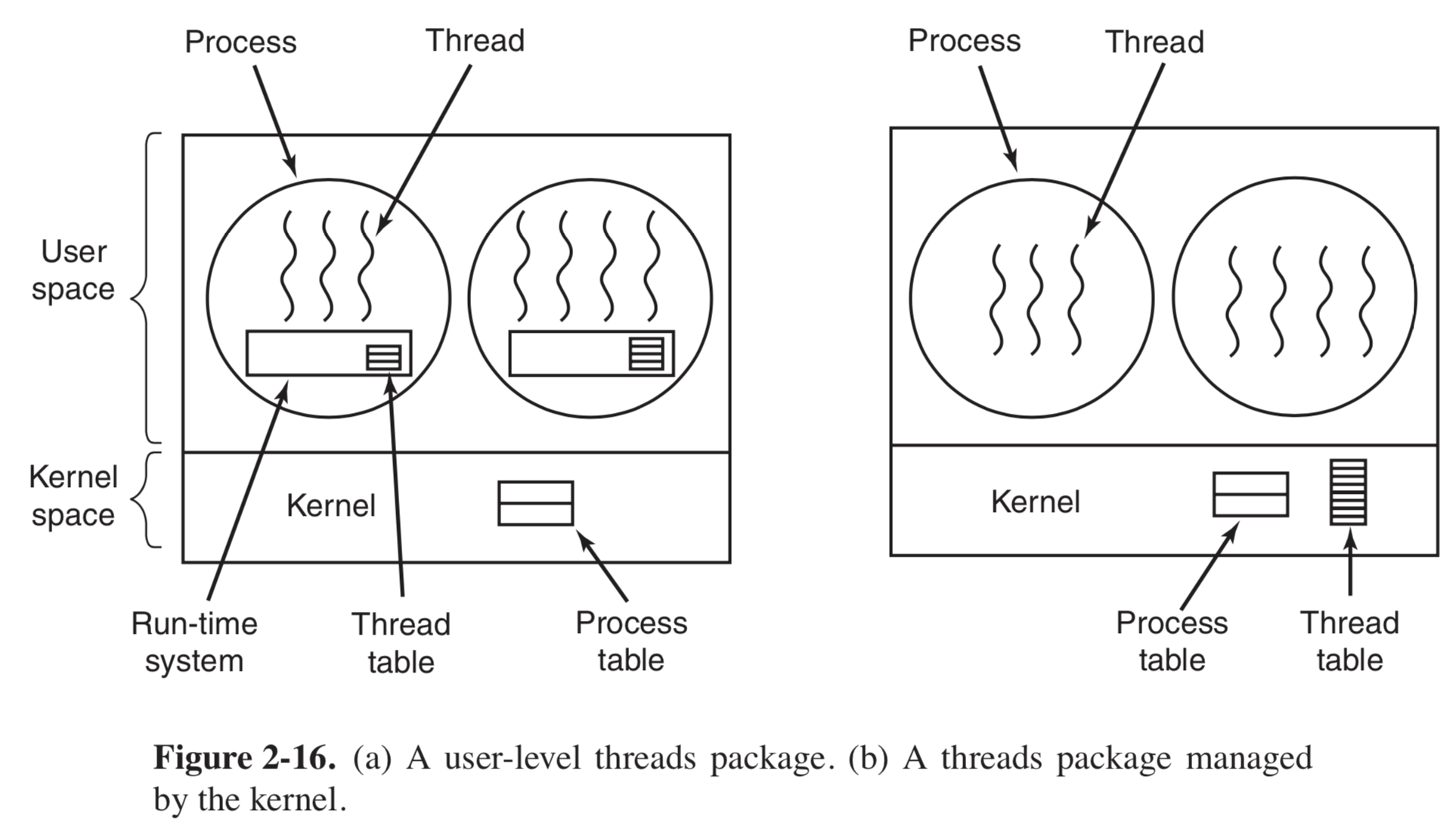
用户空间中实现线程: 把整个线程包放在用户空间中,内核对线程包一无所知。从内核的角度考虑,是按照正常的方式管理,即单线程进程。
用户空间管理线程如图 2-16(a), 每个进程需要有其专属的的线程表(thread table),用来追踪该进程中的线程。这些线程表和内核中
的进程表类似,不过他仅仅记录各个线程的属性,如每个线程的程序计数器,堆栈指针,寄存器和状态等。该线程表由运行时系统管理。
用户空间中实现线程的优点:
1. 用户级线程包可以在不支持线程的操作系统上实现
2. 用户空间的线程切换比陷入内核切换要快一个数量级(或更多)
当某个线程引起本地阻塞后,它调用一个运行时系统过程,该过程检查该线程是否必须进入阻塞状态。如果是,它在线程表中保存
该线程的寄存器(即它本身的),查看表中可运行的就绪线程,并把新的线程的保存值重新装入机器的寄存器中。只要堆栈指针
和程序计数器一被切换,新的线程就又自动投入运行。如果机器有一条保存所有寄存器的指令和另一条装入全部寄存器的指令,
那么整个线程的切换可以在几条指令内完成。
3. 允许每个进程有自己定制的调度算法。
用户级线程具有较好的扩展性,因为在内核空间中内核线程需要一些固定表格空间和堆栈空间,如果内核线程数量非常大,就会
出问题。
用户级线程的问题:
第一:如何实现阻塞系统调用。
由于用户线程包对内核是透明的,用户的任何一个线程进行阻塞系统调用,会导致该进程下的所有线程被阻塞。使用线程的一个主要目标
是,首先要允许每个线程使用阻塞调用,但是还要避免被阻塞的线程影响其他的线程。
第二:如果一个线程开始运行,那么在该进程中的其他线程就不能运行,除非第一个线程自动放弃CPU。
单独的进程内部,没有时钟中断,不能用轮转调度的方式调度进程。
第三:与阻塞系统调用问题类似的缺页故障
内核级线程模型:在内核中记录系统中所有线程的线程表。当某个线程希望创建或销毁一个线程时,进行一个系统调用,这个系统调用通过对线程表的更新完成线程的创建和销毁。如图2-16 (b)
内核线程的实现原理:内核的线程表保存了每个线程的寄存器,状态和其他信息。这些信息和在用户空间中(运行时系统)的线程是一样的,但是现
在保存在内核中。这些信息是传统内核所维护的每个单线程进程信息的子集。另外,还维护了传统的进程信息。
内核线程的优势:
1. 所有能够阻塞线程的调用都以系统调用的形式出现。
当一个线程阻塞时,内核可以选择调用同一个进程的另一个线程(若有一个就绪线程),或者运行另外一个进程中的线程。相比,在用户空
线程中,运行时系统只能运行自己进程内的线程,知道内核剥夺它的CPU(或没有可运行的线程)为止。
2. 内核中不需要任何新的,非阻塞的系统调用。当出现阻塞和缺页故障时候,可以很方便的检查该进程是否有任何其他可以运行的线程。
内核线程的问题:
在内核中创建和销毁现场的代价比较大。
(线程池,控制线程的回收和循环利用,是一种有效降低线程开销的方法)
内核线程模型业引入了其他更多的复杂问题:
在一个多线程进程创建新进程时,新进程是否拥有和原进程相同数量的线程还是只有一个线程?
如果多个线程都注册了一个信号,当信号到达时,如何调度线程?
混合线程模型
为了结合用户级线程和内核级线程的优势,就出现了混合线程模型。该模型如图 2-17
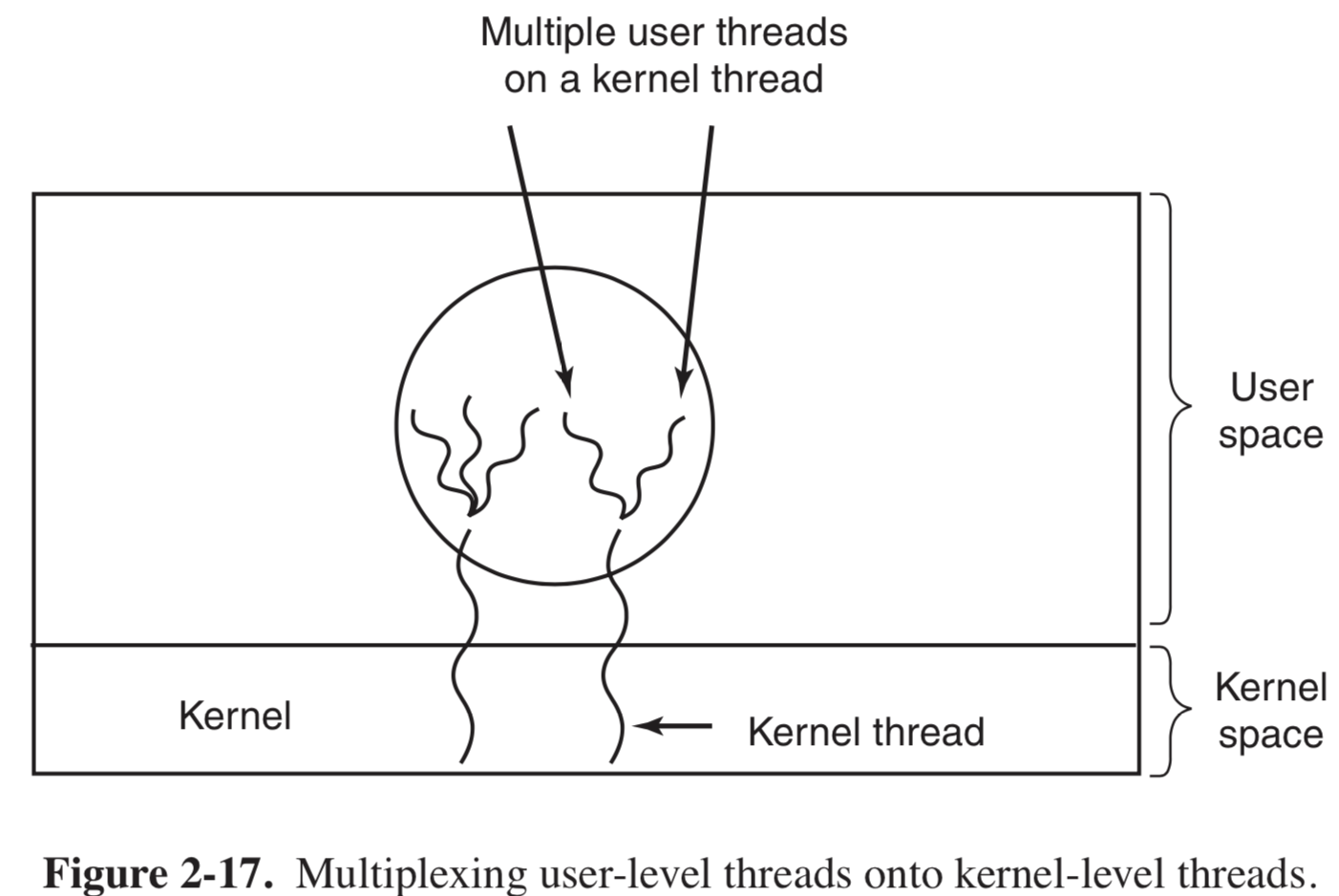
该模型,是用内核级线程,将用户级线程与某些或着全部内核线程多路复用起来。编程人员可以决定有多少个内核级线程和多少个用户级线程彼此多路复用。
优势:内核只识别内核级线程,对其调度。每个内核级线程,有一个可以轮流使用的用户基级线程集合。
混合线程模型需要解决一个核心的问题是:如果线程阻塞在某个系统调用或页面故障上,只要同一个进程中有任何就绪的线程,就应该有可能运行其他的线程。避免用户空间和内核空间不必要的切换,从而提升效率。
实现机制: 调度程序激活机制
内核给每个进程安排一定数量的虚拟处理器,并且让(用户空空间)运行时系统将线程分配到处理器上
当内核了解到一个线程被阻塞之后(例如:由于执行了一个阻塞系统调用或产生了一个页面故障),内核通知该进程的运行时系统,并且在
堆栈中以参数形式传递有问题的线程编号和发生事件的一个描述。内核通过一个已知的起始地址启动运行时系统,从而发出了通知,这是
对UNIX中信号的一种粗略模拟。这个机制称之为 上行调用
一旦如此激活,运行时系统就重新调度其线程,这个过程通常是这样:
把当前线程标记为阻塞并从就绪表中取出另一个线程,设置其寄存器,然后在启动之。稍后,当内核知道原来的线程有可云心时(例如:原
先试图读取的管道中又了数据,或已从磁盘中读入了故障的页面),内核就一次又上行调用运行时系统,通知它这一件事情。此时,该运行
时系统按照自己的判断,或者立即重启被组赛的线程,或者把它放入就绪表中稍后运行。
协程
协程定义
V1: 协同程序是一种计算机程序组件,它通过允许暂停和恢复执行,将子程序泛化以实现非抢占式的多任务处理。
Coroutines are computer program components that generalize subroutines for non-preemptive multitasking,
by allowing execution to be suspended and resumed
V2: 协程是一个函数,它可以暂停执行以在以后恢复,是无堆栈的。它通过返回调用方来暂停执行,恢复执行需要的数据与堆栈分开存储。使得可以进行异步执行顺序代码
A coroutine is a function that can suspend execution to be resumed later. Coroutines are stackless: they
suspend execution by returning to the caller and the data that is required to resume execution is stored
separately from the stack. This allows for sequential code that executes asynchronously
(e.g. to handle non-blocking I/O without explicit callbacks), and also supports algorithms on lazy-computed
infinite sequences and other uses
我理解 协程 本质是一种 通过顺序代码来实现异步执行的函数机制。在降低线程切换带来开销的同时,通过系统并行执行来提升执行效率。
参考文章: